Ch2. Business Problems and Data Science Solution
- 숙명여자대학교 소프트웨어학부 데이터사이언스개론 - 박동철 교수님
# Data Science Process
- data science의 원리
> data mining은 상당히 이해되는 단계임 → fairly well-understood = systematic
- Data science의 과정
> data scientist들은 현실세계의 문제를 substask로 나눔
> subtask들에 대한 해결은 전반적인 문제를 해결하기 위해 구성됨

- 문제의 밑바탕이 되는 공통된 data mining task가 있음
> ex) classification, regression, clustering, association, rule discovery, ...
- 좋은 data scientist가 되기 위해서는
> 이러한 공통된 data mining task로 해결하는 것에 대해 많이 알아야 함
> 문제를 이런 공통된 task끼리 분해하는 능력을 가져야 함
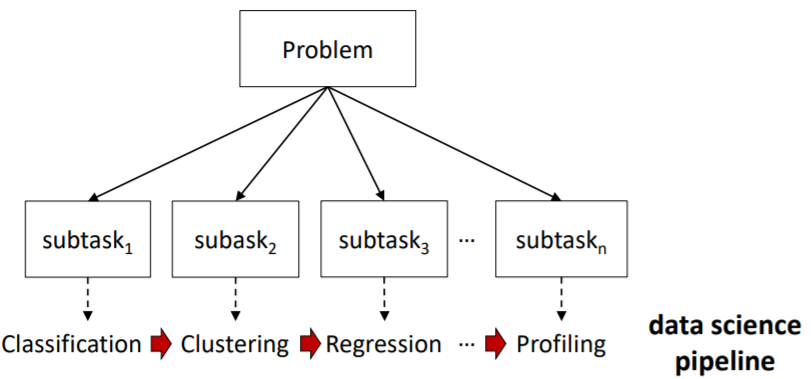
* pipeline: 병렬처리 (독립적으로 작동 가능)
# Common Data Mining Tasks
- 많은 수의 특정 data mining 알고리즘에도 불구하고 근본적으로 다른 data mining은 극히 일부에 불과함
① Classification - 분류
② Regression (a.k.a. value estimation) - 회귀분석 (값 예측)
③ Similarity matching - 유사도 매칭
④ Clustering - 군집화: 유사 데이터끼리 묶는 것
⑤ Co-occurrence grouping (a.k.a. association rule discovery) - 동시 발생/ 연관성 규칙 발견
⑥ Profiling (a.k.a. behavior description) - 행동 묘사
⑦ Link prediction - 연관성 예측
⑧ Data reduction - 불필요한 데이터 제거 or 데이터 형태를 바꿈
⑨ Casual modeling - 인과 관계 모델링
# 1. Classification
- 각각의 데이터가 어느 class 집단에 속하는지 예측하는 것
→ which of a set of classes this individual belongs to
> 일반적으로 class들은 상호 배타적이다 ex) Yes이면서 No인 것은 없음
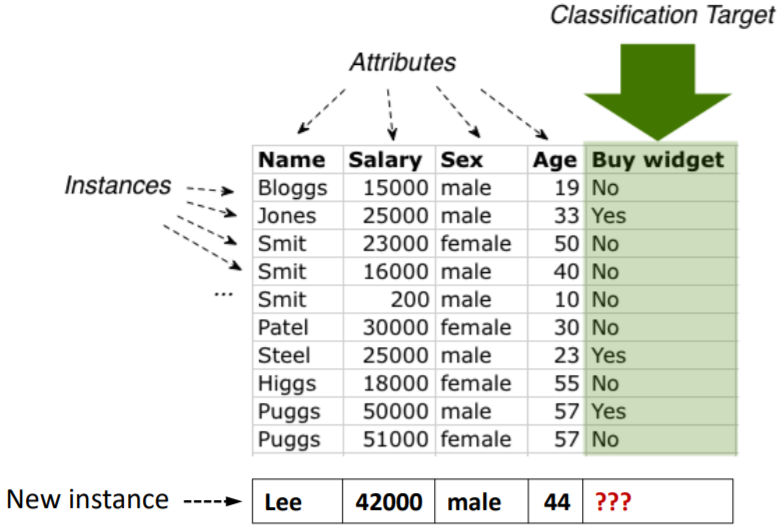
* classification target: 분류하고자 하는 target
* Buy widget → Yes or No로만 분류되고 있음
* New instance의 ??? 를 예측하는 것 → classification
- 일반적인 과정
> training dataset이 주어지면, data의 classes를 묘사하는 모델을 구축함
> 새로운 individual이 주어지면, 그것의 class를 추정하는 과정에 모델을 적용함

- A similar task: 점수 또는 클래스 확률 추정 → scoring or class probability estimation
> 새로운 individual이 각 클래스에 속할 확률을 만듬
ex) (Lee, 42000, male, 44) → (Yes: 80%, No: 20%)
# 2. Regression
- 각 individual에 대해, 그 individual이 속하는 어떤 변수의 숫자 값을 추정 또는 예측하는 것 → numerical value
> 값 추정이라고도 함
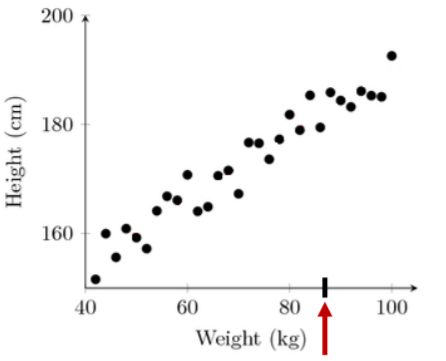
ex) 무게가 주어질 때, 그 사람은 키가 몇일까? → x값이 주어질 때 y값을 예측하는 것
- 일반적인 과정
> training dataset이 주어지면, 각 individual의 특정 변수의 값을 보여주는 모델을 구축
→ the value of the particular variable specific to each individual

- Regression vs. classification
> classification: instance의 class를 예측 ex) Yes/No
> regression: instance와 연관이 있는 값을 예측
# 3. Similarity Matching
- 유사한 개인에 대해 알려진 데이터를 기반으로 비슷한 개인을 식별함
→ identify similar individual based on data known about them

ex )어떤 user가 user 1과 비슷한가? / 어떤 item이 item 3와 비슷한가?
- 일반적인 과정
> 두 individual 사이의 거리에 대한 척도를 정의함 → Define a distance measure
* 유사하다는 기준을 정하는데 거리를 사용하며 거리가 가까울수록 유사도가 높은 것임
> individual이 주어지면 거리를 최소화하는 individual들을 찾음 → individuals that minimize the distance

# 4. Clustering
- 군집화: 답을 모르는 상태에서 거리가 가까운 individual들 끼리 묶는 것 → 거리가 가깝다 : similar하다
> 거리 측정은 두 individual 사이의 유사성을 결정하는데 사용됨
→ distance measure: determine the similarity

- data 안에 존재하는 자연스러운 그룹을 보는 것에 매우 유용하다 → natural: 답을 모르지만 자연스럽게 분류
> ex) 어떤 종류의 고객이 있는가?
# 5. Co-occurrence grouping
- 두 entites 사이의 관련성이나 동시 발생을 찾는 것 → Find associations or co-occurrence
> ex) 어떤 item들이 같이 공통적으로 구매되는가?

An axxociation rule: {Diapers} → {Beer}
" 귀저기를 사는 고객은 맥주를 사는 경향이 있음"
- marketing에 매우 유용
> 특별 프로모션, 상품 진열, 상품끼리의 조합을 제공하는데 있어서 유용
> 추천 → X물건을 사는 사람이 Y물건을 사는 경향이 있음
# 6. Profiling
- 개인이나 집단의 전형적인 행동을 특징지음 → characterize the typical behavior
> 행동 묘사라고도 부름

- 일반적이지 않은 일을 감지하는데에 있어 매우 유용 → anomaly detection
> profile은 일반적인 행동을 묘사함
> 최근 행동이 profile과 매우 다르다면, 경보를 울림
> ex1) 미국에서만 사용하던 카드를 한국에서 사용했을 때 사용자에게 카드회사로부터 연락이 옴
> ex2) 사기 탐지: 일반적으로 하는 신용 카드로 구매하는 것의 종류에 대해 profile을 가지고 있다면,
평소 사지 않던 물건을 해당 신용카드로 사게 되면 알람이 울림
# 7. Link Prediction
- data item들 사이의 관계를 예측 → predict connections between data items
> 일반적으로 link가 존재하는 것을 제안하고 그 강도를 추정함으로써 관계를 예측함

- 추천에 있어 매우 유용함
> SNS의 친구 추천 시스템
> 고객에게 영화를 추천할 때
# 8. Data Reduction
- dataset을 더 큰 dataset의 중요한 정보를 많이 포함하는 작은 dataset으로 줄임
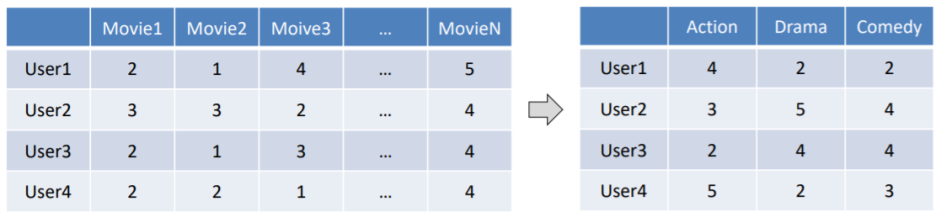
영화의 시청 여부를 선택할 때 장르가 중요한 정보라면 해당 영화가 속하는 장르로 분류할 수 있음
- advantage
> 작은 dataset이 다루거나 처리하기 더 쉬움
> 정보나 insight를 드러는데 더 나음
> 정보를 일부 손실할 수 있음
# 9. Causal Modeling
- 인과 모델링
- 사건이나 행동이 다른 이들에게 영향을 미치는 것을 이해하는 것 → influence others

흡현이 폐암을 유발하는가 아니면 그 반대인가?
- 예시
> target이 되는 소비자가 더 높은 비율로 구매한다고 가정
> 이건 targeting을 잘해서 인가 그사람들이 좋은 고객이어서 인가?
# Supervised VS. Unsupervised

- 정답을 알고 학습하는가의 차이
- Supervised data mining ex) 지도 학습
> 특정 대상을 구제화함
> ex) target: buy widget
> target을 예측하는 것이 목적임
> training dataset이 있어야 함 → target value = label
> classification, regression, casual modeling,
(similarity matching, link prediction, data reduction←likely)
* likely: 상황에 따라 supervised or unsupervised 둘 중 하나
- Unsupervised data mining ex) 비지도 학습
> 특정 대상을 구체화하지 않음
> ex) clustering: We have no specifiec target to define
> 어느 특정한 target 없이 어떤 패턴을 찾는 것이 목표
> training dataset이 필요하지 않음
> clustering, co-occurrence grouping, profiling
# Classification VS. Regression
- 둘 다 supervised data mining task임 → target의 유형에 따라 구분됨
- classification
> target: category가 있는 값 (주로 값이 두개 중 하나인 경우) ex) YES/NO, High/Mid/Low
- regression
> target: 숫자 값
# Data Mining and Its Results
- data mining의 두 가지 단계

* target = class
> mining phase: 이미 존재하는 data로부터 패턴을 찾거나 모델을 구축함
* ?: 값이 정해지지 않은 상태
> use phase: 패턴과 모델을 새로운 데이터에 적용함
# Data Mining Process
- CRISP - DM: 산업을 통틀어 표준회된 Data mining 과정
> 문제에 구조를 배치하는 잘 이해된 프로세스

① Business Understanding
> 해결해야 하는 문제를 이해하는 것
> 해결해야 하는 문제를 하나 이상의 data science 문제로 간주함
> 각 data science 문제에 대한 해결책을 만듬
> 문제를 재현하고 해결책을 설계하는 것은 반복적 발견 과정임 → iterative process
② Data Understanding
> Data: 해결책을 만들 때 사용 가능한 재료
> 각 데이터의 강점과 한계점을 이해해야 함 → 왜냐하면 거의 그 문제와 정확히 일치하는 것이 없기 때문
strength/limitation
> 필요한 데이터에 더 투자 할지 말지를 결정
→ 무료인 데이터도 있지만 얻기 위해 구매해야하는 데이터도 있기 때문
③ Data Preparation
> 데이터를 더 사용하기 좋은 형태로 삭제하고 변형함
→ 데이터 분석 tool이 특정한 형태의 데이터를 요구하기 때문
> data mining 결과의 품질은 이 단계에 따라 크게 달라짐
④ Modeling
> data mining 기술이 데이터에 적용되는 데 있어 주요 단계임
> output: 데이터의 규칙성을 포착하는 일종의 모델 또는 패턴
> 근본적인 data mining의 idea들을 이해하는 것이 매우 중요함
→ data mining 기술 그리고 존재하는 알고리즘
⑤ Evaluation
> data mining의 결과를 엄격하게 평가함
> 예시
1. 모델의 예측 정확도를 측정
2. training data외의 model의 일반성을 확인
3. 거짓 경보 발생률을 추정
> 결과를 즉시 배포하는 대신, 통제된 실험실에서 먼저 모델을 테스트하는 것이 좋음
→ 이것이 배포하는 것보다 쉽고, 싸고, 빠르고 안전함
> data scientist는 이해관계자에게 쉽게 그 모델과 그것의 평가 결과를 설명할 수 있어야 함
* stakeholders(이해관계자): managers, executives, programmers, ...
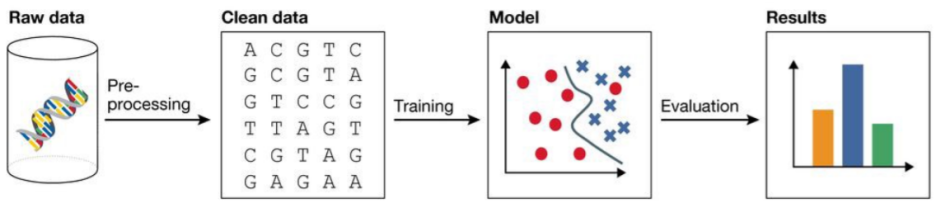
⑥ Deployment
> data mining(혹은 system)의 결과를 실제 사용에 적용하는 것 → real use
> 일반적인 시나리오: 새로운 모델이 시행되면 그 모델은 존재하는 정보 시스템과 통합됨 → implimented
> In many cases
- Data Science teams: 작동하는 prototype을 만들고 그것을 평가함
- Data engineering teams: 모델을 생산 시스템으로 시행함
> 시행한 이후, 그 과정은 첫 번째 단계로 돌아감
→ 이전 순환에서 얻은 이해와 경험을 사용함으로써 다음 순환은 향상된 해결책을 만들 수 있음
# Other Analytics Techniques & Technologies
- data mining 외에, 데이터의 분석을 위한 기술이 다양함
- 이런 기술을 숙지하는 것이 중요함
> 그것의 목표는 무엇인지?
> 그것들의 역할은 무엇인지?
> 그것들의 차이는 무엇인지?
- data scientist 에게 중요한 기술은 어떤 종류의 분석 기술이
특정 문제를 해결하는 데 적합한지 인식할 수 있는 것임
① Statistics
> 분석의 근간을 이루는 많은 지식을 제공함
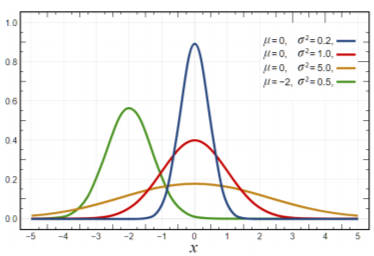
> 예시
- 데이터 요약 → Data summary
- 다른 데이터 분포에 대한 이해 → understanding differnet data distributions
- 검정 가설 → testing hypotheses
- 정량화 불확실성 → quantifying uncertainty
- 상호관계 측정 → measuring correlation
- 모델이나 패턴을 추출하기 위한 많은 과정의 근본은 통계이다
→ root in Statistics
② Database Querying
- Database system: 데이터를 삽입, 질의, 업데이트 및 관리할 수 있는 소프트웨어 응용 프로그램
- Database query
> 데이터 또는 데이터에 대한 통계에 대한 특정 요청
> 기술적인 언어로 형식화되어있고 database system에서 사용됨 ex) SQL
SELECT name, address FROM customers WHERE age>25 AND gender = 'Female' AND domicile = 'CA'
- Data science vs. databases technologies
> Data science는 data base system에 저장된 관심있는 데이터를 조사하거나 찾을 때
database technology를 사용할 수 있음

③ Machine Learning
- 컴퓨터 시스템에게 명시적 프로그래밍 없이 data를 통해 학습할 능력을 주는 것
> AI의 하위 분야임
- data를 사용하여 모델을 발전시키고 향샹시킴 → 목적

- data mining과 machine learning은 밀접하게 연결되어 있음
→ data mining 분야가 machine learning의 가지(offshoot)로 여겨짐
> KDD (Knowledge Discovery and Data mining)
> 둘 사이에 기술과 알고리즘이 공유됨
> 유용하고 유익한 패턴을 데이터로부터 찾음
- machine learning은 많은 수행 향상의 유형 그리고 권한과 인지의 문제와 더 관련있음
- data mining은 data로부터 패턴과 규칙성를 찾는 것 그리고 상업적인 적용과 사업적인 이슈에 더 관련있음
# Example of Applying These Techniques
- "수익이 가장 좋은 고객은 누구인가?" → Database systems
- " 정말 수익성이 높은 고객과 일반 고객의 차이가 있는가?" → Statistics (hypothesis testing)
- " 하지만 이 고객들은 정말 누구이고 특징을 알 수 있는가? → data mining (profiling)
- " 일부 신규 고객은 수익성이 있는가? 얼마나 되는가? → data mining (classification, regression)
# Summary
- There is a well-defined data mining process (CRISP-DM)
> Business understanding → data understanding → data preparation
→ modeling → evaluation → deployment
- A data scientist typically decomposes a problem into one or more common data mining tasks
> classification, regression, similarity matching, clustering, association rule discovery, profiling,
link prediction, data reduction, causal modeling
> understand the fundamentals of these tasks
- Other related data analytics technologies
> statistics, database querying, machine learning
> Though their boundaries are not always sharp, it is important to know
about other techniques' capabilities to know when they should be used
'Study > Data Science' 카테고리의 다른 글
| [DataScience] Ch6. Similarity, Neighbors, and Clusters (0) | 2021.08.24 |
|---|---|
| [DataScience] Ch5. Overfitting and Its Avoidance (0) | 2021.08.24 |
| [DataScience] Ch4. Fitting a Model to Data (0) | 2021.08.23 |
| [DataScience] Ch.3 Introduction to Predictive Modeling: From Correlation to Supervised Segmentation (0) | 2021.08.23 |
| [DataScience] Ch1. Data-Analytic Thinking (0) | 2021.08.23 |
