
1. Ch10. Representing and Mining Text
- 숙명여자대학교 소프트웨어학부 데이터사이언스개론 - 박동철 교수님
1.1. # Dealing with Text
- 우리 입맛대로 feature vector에 맞게 data가 주어지지 않음
- tool에 맞게 데이터를 가공하거나 (representation engineering = preprocessing)
데이터에 맞는 tool을 새로 설계함 // 전자의 방법이 효율적이기 때문에 일반적으로 사용
- text data: 여러 분야에서 text data를 다루고 mining하며 분석하기 때문에 큰 부분을 차지
1.2. # Why Text is Important
- text는 어디에나 있음
> 많은 기존의 적용에서 text를 만들어내거나 기록함 ex) 진료 기록
> 멀티미디어 데이터가 많은 양의 데이터를 차지하지만 text를 포함하고 있기 때문임
→ text를 통해 많은 양의 data를 포함하는 것
- 비지니스 환경에서도 많이 쓰임
> 고객의 피드백을 받아야 할 때 등
> 고객과 소통을 위해서는 여전히 text가 중요함
1.3. # Why Text is Difficult
- text: 사람들이 심리적으로 쉽다라고 느낌
> 눈에 보이고 직관적으로 이해가 쉽기 때문 하지만 사실 단순하지 않음
> 전반적으로는 unstructured함 하지만 모두 그런것은 X ex) 날짜, 요일 등..
> 주어, 목적어, 서술어 등 구조가 있는 것 같지만 이것은 언어학적인 측면에서의 구조임
인간이 이해하기 위한 구조지 컴퓨터를 위한 것 X
> 문서가 주어질 때 단어를 분리하여 feature vector를 만드는 과정에서 단어의 순서가
중요할 수도 있고 아닐 수도 있음 → 따라서 rule이 필요함
- text가 데이터로서 가치를 가지려면 rule이 필요함
> text의 문법이 다 맞는 것은 X ex) 문장을 랜덤하게 마침
> 유의어, 동음이의어, 축약어 등..
특히 축약어는 컴퓨터가 rule을 찾아내지 못할 수 있어 의미상실 가능성있음
> text는 문맥에 따라서도 의미가 달라짐 ex) 잘한다 잘해 ~ → 진짜 잘하는건지 아님 비꼬는건지?
- text는 preprocess 과정이 필요
1.4. # Text Representation
- 목표: 문서의 set을 feature vector로 바꾸어야 함
> 하나의 문서가 하나의 instance가 되는 것
> feature vector가 무엇이 될지는 미리 알 수 없음 → 우리가 뽑아서 만들어내야 함
- 용어
> 문서 즉, document는 token(word) 혹은 용어(term)으로 구성됨
> corpus: document의 모음(collection)
1.5. # Bag of Words
- document가 word의 집합이다 라고 바라보는 것
> 문법, 단어의 순서, 문장의 구조, 구두점 모두 무시
> 모든 단어를 중요한 keyword라고 생각하며 단어 자체가 feature vector가 됨
> 단어가 해당 document에 있으면 1 없으면 0
- 직관적으로 표현됨
- 복잡도가 높지 않음 → inexpensive
- 많은 task들에서 잘 작동함
1.6. # Term Frequency (TF)
- word counting
> 단어들이 document에 몇 번 나타났는지 count

- Pre-processing
1. 대문자를 소문자로 바꿈
> iPhone, iphone, IPHONE → 모두 iphone으로 바꿈 (같은 단어로 인식)
2. 단어의 원형을 제외하고 모두 제거 (stemmed)
> 접미사 제거
> 동사원형으로 바꾼다고 생각 ex) 복수형의 -s/-es 제거, 시제 표현 제거
> 기계적으로 자르기 때문에 원형의 스펠링이 정확하지 않을 수 있음
모든 document에서 동일한 과정으로 처리되면 스펠링 정확하지 않아도 괜찮음
3. stop word를 제거
> 전치사, 관사 제거
a, the, of, on, and 등등
> 너무 자주 등장하고, 큰 뜻을 가지지 않기 때문임
- example: more complex sample document
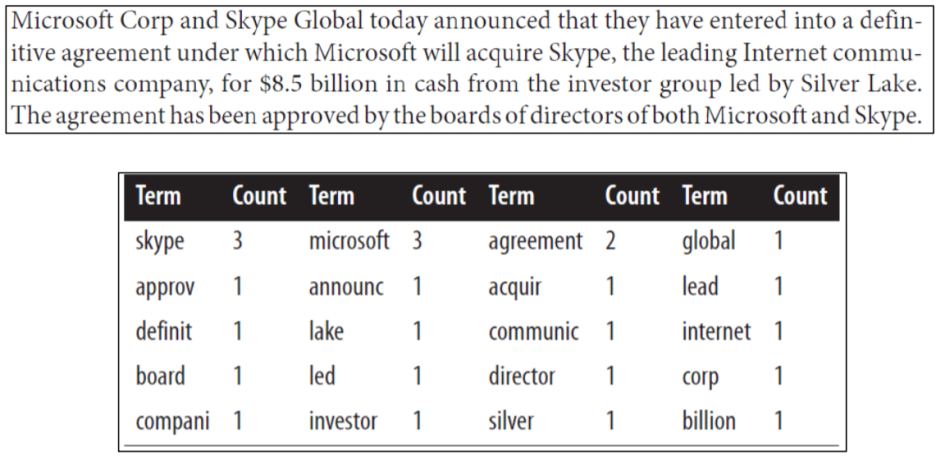
> 선처리로 단어를 형태를 바꾼 후 count → sorting
1.7. # Normalized Term Frequency
- 단어가 자주 나타난다 해서 중요하다고 할 수 있는가?
> document가 길어서 frequency가 높은 것을 가지고는 무조건 중요하다고 할 수 X
- normalized 방법
> word frequency를 전체 document의 길이로 나눠줌
→ document의 길이에 따라 생길 수 있는 위의 문제를 해결해줌
> corpus에서 특정 용어의 빈도수로 나눌 수도 있음
> 용어의 count만 따지면 안되고 normalized 과정을 중요시 해야 함
1.8. # Inverse Document Frequency (IDF)
- document의 frequency에 초점
> 전체 corpus에서 단어가 얼마만큼 자주 나타나는가
> 전에 document에서 그 단어를 포함하고 있는 document는 얼마나 많이 있는가
> 위와 같은 관점을 가지고 mining을 함
- 단어가 너무 자주 나타나거나 너무 나타나지 않으면 분류나 군집화에서 의미가 없음
- TF에 대해서 낮고 높음의 한계를 지정
- 더 적은 document에서 용어가 발생할 수록 더 meaningful한 단어이기 때문에 inverse가 붙음
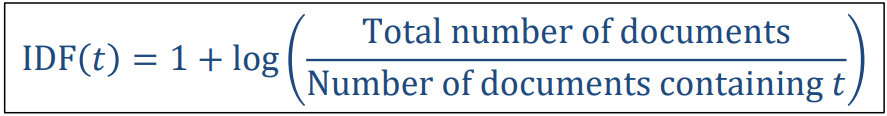
> 일반적인 상식의 반대 전체/특정 값 으로 구성되어있음
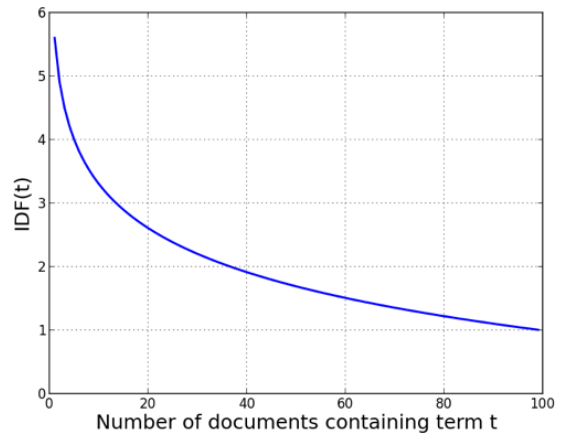
> IDF가 1에 수렴
> Number of documents containing term t가 작을수록 IDF가 큼
1.9. # Combining TF and IDF : TF-IDF

- TF-IDF(t, d)의 값은 single document에 대해 정해지지만 IDF는 전체 corpus에 대해 정해짐
- 각 document는 feature vector가 됨
- corpus는 feature vector의 집합임
- feature selection
> 단어의 개수에 대해 최소/최대 임계선 잡기
>중요도에 따라 rank에 대한 information gain 매기기
1.10. # Example: Jazz Musicians

> 적은 document에서도 각각의 단어로 세면 feature가 2000개가 넘음
1. stemming
> 동사원형으로 변형
> "Kansas" 또는 "famous"는 복수형이 아닌데도 복수형으로 인식되서 s가 빠짐
원형대로 잘라내지 않더라도 괜찮음 모든 document에서만 적용되면 됨
2. stopword 제거
- 단어의 빈도수 또는 document의 길이를 사용해 normalized 과정 필요
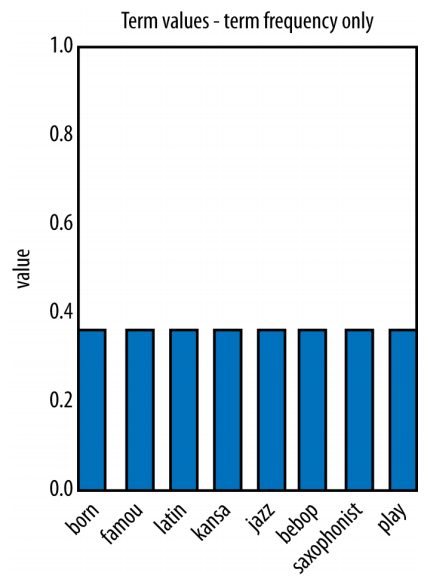
3. TF-IDF로 나타내기
- 단일 document의 feature vector가 되는 것
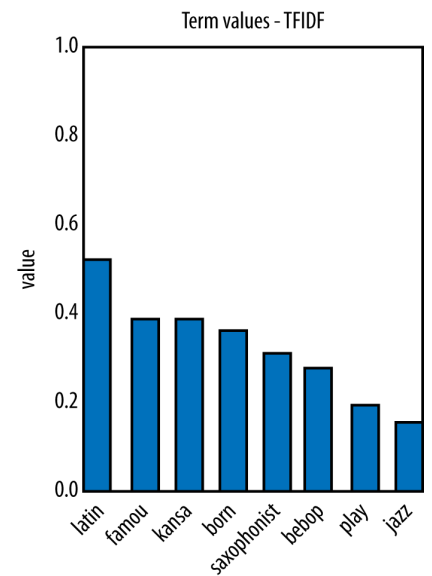
> play, jazz같은 단어는 15개의 document에서 자주 등장함을 알 수 있음
- "Famous jazz saxophonist born in Kansas who played bebop and latin"을 검색했을 때 검색 엔진은 어떻게 동작할까?
> TF-IDF로 만든 feature vector랑 document를 가지고 cosine 유사도를 구함
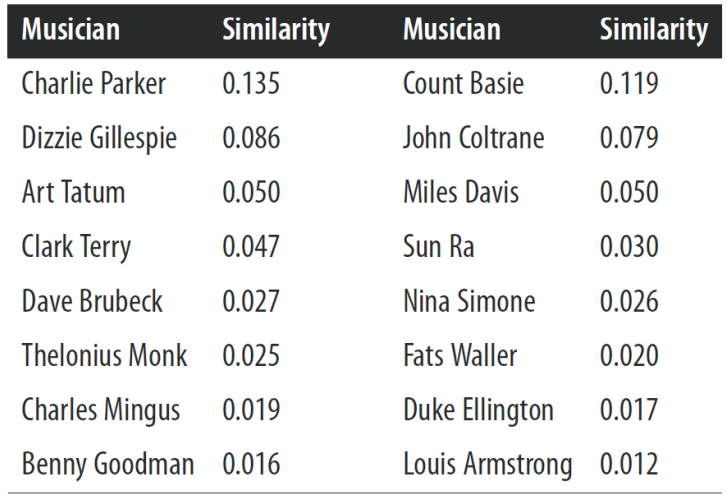
> Charlie Parker의 일대기가 가장 유사한 document임
1.11. # Beyond "Bag of Words"
- Bag of Words (TF-IDF)
> data scientist들이 text를 가지고 mining할 때 가장 먼저 고려
> 하지만 더 복잡한 것을 요구하는 application이 존재
① N-gram Sequence: 순서 중요
② Named Entity Extraction: 개체명 추출
③ Topic Models: topic 단위로 추출
1.12. # N-gram Sequences
- 단어의 순서가 중요
- 단어 그 자체 뿐 아니라 n개씩 짝지은 token도 따짐
- 줄여서 n-grams라고 많이 함 (2개씩 짝지으면 bi-grams라고 부름)
- "Bag of n-grams up to three
> individual words, adjacent word pairs, adjacent word triple 이렇게 세가지 정보를 보여줌
- 장점
> 만들기 쉬움: 언어학적인 지식 필요없고 복잡한 parsing 알고리즘 필요 없음
- 단점
> 복잡도 증가: feature set의 크기가 증가함
1.13. # Named Entity Extraction
- Entity: 여기서의 의미는 term or word. 즉, 의미를 가지는 객체
ex) 이름, 지명, 제목 등..
- 우리는 구문 추출에 있어서 더 정교하고 싶음
> 단어의 구성이 하나의 unique한 개체로 작용함. 즉, id 값을 갖는 것
- Named entity extraction 방법은 사전에 미리 지식이 필요함
> large corpus를 통해 미리 trained하거나 manually하게 분석하기 위해 사람이 정보를 입력해야 함
기계적으로 분석하기에는 한계가 존재함
1.14. # Topic Models
- 앞에서는 단어 자체를 가지고 분류 → 이것만으로는 뭔가 부족
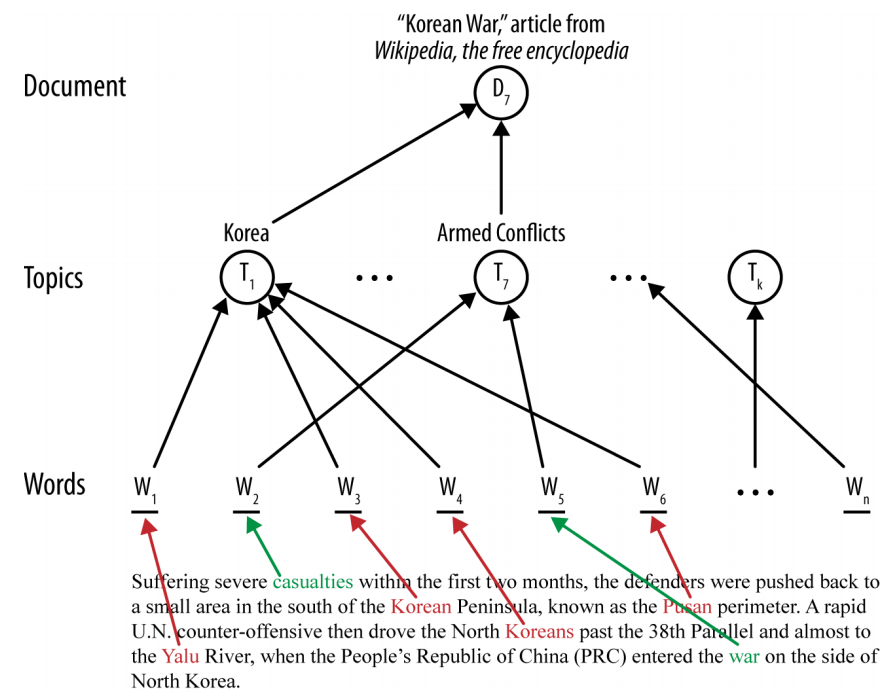
- 많은 document에서 각각 topic을 따로 뽑아냄
> document: 단어들의 squence로 구성됨
> word: 하나 혹은 그 이상의 topic과 연결됨
> topic은 모델링을 해 학습시켜 만들어짐
> topic: word들의 classification or clustering
1.15. # Example : Mining News Stroies to Predict Stock Price Movement
- 뉴스를 보고 해당되는 회사들의 주식값이 어떻게 변할지 예측
> 변동을 예측
> 어려움
- 간단한 가정
1. 같은 날. 즉, 가까운 미래를 예측
2. 숫자값을 정확하게 예측하는 것은 힘듬
> classification해서 변할지 안변할지만 고려
3. 작은 값보다는 큰 값에 중점을 두고 예측
4. 뉴스를 보고 숫자값의 변동을 예측하는 것은 어려움
> specific하게 뽑아내기
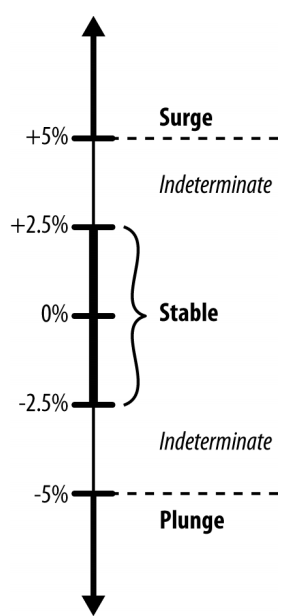
stock price가 급등하거나 급하할 때 합쳐서 change라는 class로 분류
- ~+-2.5는 no change
- +-2.5 ~ +-5까지는 분류하지 않음
- 1999년대 뉴욕 주식 변화와 나스닥에 대한 historical data
> 개장부터 폐장까지의 주요 주식들의 가격에 대한 데이터: 주식 가격의 변동 폭을 예측 가능
> 일년 동안의 재정과 관련된 뉴스들과 주식의 관련성에 대한 data
- A sample new story

- 일년 동안의 Summit Technology를 사용한 회사의 주식 변동
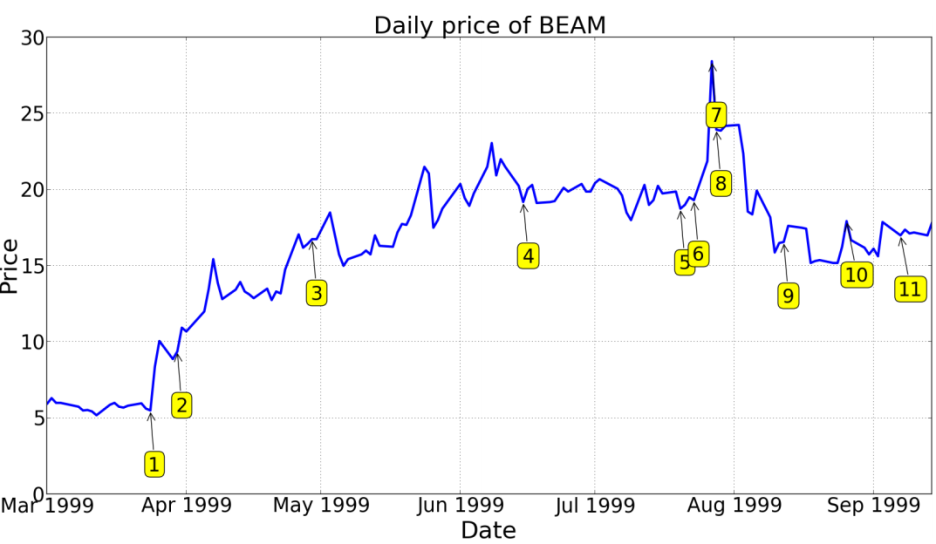
> 1번 뉴스가 나온 이후로 급증
- 뉴스 요약본

- data processing
> 36000개의 data processing: 대문자를 소문자로 바꿈, stemmed, remove stop word, n-grams...
> targging된 stories 중 75%는 변하지 않고 25%는 변함
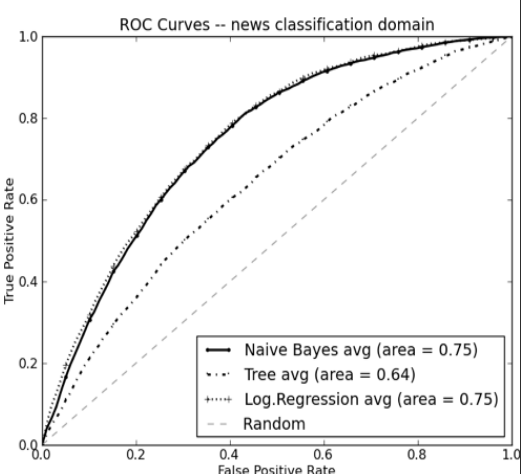
ROC curve
> 10-fold cross validation의 평균 결과
여기서는 NB, LR이 tree보다 성능이 좋음
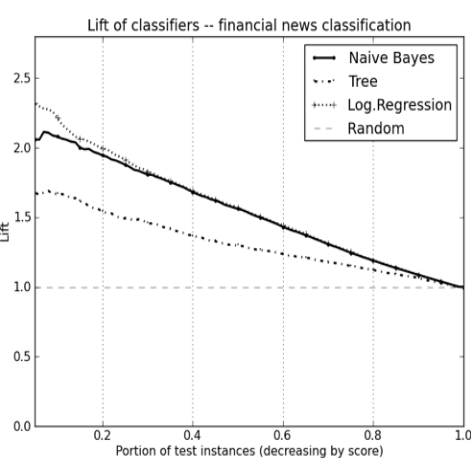
Lift Curve
> 얼마만큼 정확도가 높은지 보여줌
20%만 targeting 하게되면 NB, LR model이 random model보다 2배 높은 정확도를 보여줌
- information gain 부여하기
> 36000개의 뉴스기사 단어들 중 stock price에 큰 영향을 미치는 단어를 뽑아봄

'Study > Data Science' 카테고리의 다른 글
| [DataScience] Ch9. Evidence and Probabilites (0) | 2021.08.24 |
|---|---|
| [DataScience] Ch8. Visualizing Model Performance (0) | 2021.08.24 |
| [DataScience] Ch7. Decision Analytic Thinking 1: What is a Good Model? (0) | 2021.08.24 |
| [DataScience] Ch6. Similarity, Neighbors, and Clusters (0) | 2021.08.24 |
| [DataScience] Ch5. Overfitting and Its Avoidance (0) | 2021.08.24 |
