Chapter 03. 언어 설계와 파서 구현
프로그래밍 언어론 원리와 실제 - 창병모 교수님
3.1 프로그래밍 언어 S
1) 언어 설계 목표
- 간단한 교육용 언어로 쉽게 이해하고 구현할 수 있도록 설계한다
- 대화형 인터프리터 방시으로도 동작할 수 있도록 설계한다
- 프로그래밍 언어의 주요 개념을 쉽게 이해할 수 있도록 설계한다. 수식, 실행 문장, 변수 선언, 함수 정의, 예외 처리, 타입 검사 등을 포함한다.
- 블록 중첩을 허용하는 블록 구조 언어를 설계한다. 전역 변수, 지역 변수, 유효범위 등의 개념을 포함
- 실행 전에 타입 검사를 수행하는 강한 타입 언어로 설계한다. 안전한 타입 시스템을 설계하고 이를 바탕으로 타입 검사기를 구현
- 주요 기능을 점차적으로 추가하면서 이 언어의 어휘분석기, 파서, AST, 타입 검사기, 인터프리터 등을 순차적으로 구현
2) 언어 S의 설계
- 언어 S의 프로그램: 명령어(<command>)들로 구성됨
- 명령어(<command>)
- 변수 선언(<decl>)
- 함수 정의(<function>)
- 실행 문장(<stmt>)
- 언어 S의 구문법을 정의하는 EBNF
[언어 S의 문법]
<program> → { <command> }
<command> → <decl> | <stmt> | <function>
<decl> → <type> id [=<expr>];
<stmt> → id = <expr>;
| '{' {<stmt>} '}'
| if ( <expr> ) then <stmt> [else <stmt>]
| while ( <expr> ) <stmt>
| read id;
| print <expr> ;
| let <decls> in <stmts> end;
<stmts> → { <stmt> }
<decls> → { <decl> }
<type> → int | bool | string
7종류의 실행 문장: 대입문, if문(조건문), while문(반복문), read(입력), print(출력), 복합문, let(지역변수 선언 가능)
3가지 타입: int, bool, string
[언어 S의 수식 문법]
<expr> → <bexp> {& <bexp> | '|' <bexp> } | !<expr> | true | false
<bexp> → <aexp> [<relop> <aexp>]
<relop> → == | != | < | > | <= | >=
<aexp> → <term> {+ <term> | - <term>}
<term> → <factor> {*<factor> | / <factor>}
<factor> → [-] ( number | ( <aexp> ) | id ) | strliteral
비교 수식(<bexp>): 산술 수식을 관계 연산자를 사용하여 비교하는 수식
논리 수식(<expr>): 비교 수식에 논리 연산자를 사용하는 수식
[예제 1] 대화형 인터프리터 방식으로 변수 선언 혹은 시행문이 반복적으로 사용될 수 있음
>> print "hello world!";
hello world!
>> int x = -5;
>> print x;
-5
>> x = x+1;
>> print x*x;
16
>> if(x>0)
then print x; else print -x;
4[예제 2] 지역 변수를 사용하고 이를 사용하는 let 문의 예시
let int x = 0; in
x = x + 2;
print x;
end;[예제 3] 변수를 두 개 선언하고 정수를 입력받아 그 절댓값을 계산해서 출력
let int x; int y; in
read x;
if(x>0) then
y = x;
else y = -x;
print y;
end;[예제 4] 변수를 두 개 선언하고 정수를 입력으로 받아 정수의 계승 값(factorial)을 계산하여 출력
let int x=0; int y=1; in
read x;
while(x>0){
y = y * x;
x = x - 1;
}
print y;
end;[예제 5] 제곱 함수를 정의하고 이를 호출해서 그 결과 값을 출력
>> fun int square(int x) return x*x;
>> print square(5);
25
[예제 6] 간단한 계승(factorial) 함수를 재귀적으로 정의하고 이를 호출해서 그 결과 값을 출력
>> fun int fact(x)
if(x==0) then return 1;
else x*fact(x-1);
>> print square(5);
120
3.2 추상 구문 트리
1) 파서와 추상 구문 트리
- 어휘 분석기(lexical analyzer): 입력된 소스 프로그램을 읽어서 토큰 형태로 분리하여 반환
* 토큰: 키워드, 식별자, 숫자, 연산 기호 등의 의미 있는 문법적 단위로 문법의 터미널 심볼에 해당
- 파서(parser)
- 소스 프로그램을 구문 분석(파싱)하면서 프로그램 내의 문장들의 AST를 생성하여 반환
- 파싱하면서 필요할 때마다 getToken()을 호출하여 어휘 분석기에 다음 토큰을 요구함
- 추상 구문 트리(Abstract Syntax Tree, AST)
- 파서는 소스 프로그램을 파싱하여 AST를 생성
- AST는 소스 프로그램의 구문 구조를 추상적으로 보여주는 트리로 해석기의 입력이 됨
- 컴파일러 혹은 인터프리터에서 소스 코드의 구문적 구조를 표현하는 중간 표현으로 많이 사용
- 컴파일러(Compiler): AST를 순회하면서 코드를 생성
- 인터프리터(Interpreter): AST를 순회하면서 각 문장을 해석하여 수행
- 상태(State): 인터프리터는 각 문장을 수행하면서 유효한 변수들의 상태를 저장하는 스택 형태의 자료구조를 사용

2) 유도 트리
- 입력 스트링의 유도 과정을 시각적으로 보여주는 트리로 유도 과정을 자세히 보여줌
- 파싱을 한다고 해서 유도 트리가 자동적으로 구성되는 것은 아니며 단지 파싱 과정을 보여주고 설명하기 위한 것임
[수식 문법 1]
<expr> → <term> {+<term>}
<term> → <factor> { * <factor> }
<factor> → [-] (number | id | '(' <expr> ')' )
- [수식 문법 1]을 이용하여 a + b * c의 유도 과정을 트리로 그렸을 때
<expr> => <term> + <term> => <factor> + <term> => a + <term> => a + <factor> * <factor> =>* a + b * c

3) 수식의 AST
- 수식(Expr)의 AST 노드는 다음과 같이 식별자(변수 이름), 값, 이항 연산, 단항 연산으로 구분
Expr = Identifier | Value | Binary | Unnary
- 연산을 포함한 수식(Expr)은 이항 연산(Binary Operation) 수식과 단항 연산(Unary Operation)으로 구분하여 구현할 수 있음
1. 이항 연산의 AST
- Binary = Operator op; Expr expr1; Expr expr2

- 이항 연산 수식을 나타내는 Binary 노드를 정의하여 모든 이항 연산을 위한 AST 노드를 구성할 수 있음
class Binary extends Expr{
// Binary = Operator op; Expr expr1; Expr expr2
Operator op;
Expr expr1, expr2;
Binary(Operator o, Expr e1, Expr e2){
op =o; expr1 = e1; expr2 = e2;
}// Binry
}2. 단항 연산의 AST
- 이항 연산과 비슷하게 단항 연산(Unary Operation) 수식을 위한 AST 노드도 정의할 수 있음
- Unary = Operator op; Expr expr

- 단항 연산 수식을 나타내는 Unary 노드를 정의하여 모든 단항 연산을 위한 AST 노들르 구현할 수 있음
class Unary extends Expr{
// Unary = Operator op; Expr expr
Operator op;
Expr expr;
Unary(Operator o, Expr e){
op = o;
expr = e;
}// Unary
}3. 비교 및 논리 연산의 AST
- 비교 및 논리 연산을 포함하는 수식의 AST도 비슷하게 Binary 노드 또는 Unary 노드로 모두 표현할 수 있음
<expr> → <bexp> {& <bexp> | '|' <bexp> } | !<expr> | true | false
<bexp> → <aexp> [<relop> <aexp>]
<relop> → == | != | < | > | <= | >=
4) 문장의 AST
1. 변수 선언
- 변수 선언(Decl)은 타입 이름(Type)과 변수 이름(Identifier) 그리고 초기화할 수식(Expr)으로 구성
- Decl = Type type; Identifier id; Expr expr
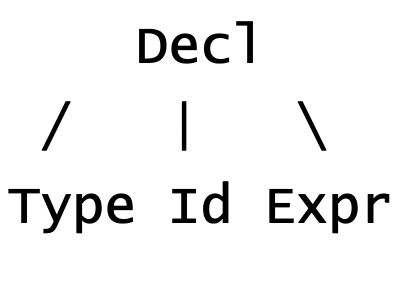
2. 대입문
- 대입문(Assignment Statement)은 변수 이름(Identifier)과 대입할 수식(Expr)으로 구성됨
- Assignment = Identifier id; Expr expr

- AST 노드는 다음과 같이 구현할 수 있음
class Assignment extends Stmt{
Identifier id;
Expr expr;
Assignment(Identifier t, Expr e){
id = t;
expr = e;
}
}3. Read문
- Read문은 변수 이름(Identifier)로 구성됨
- Read = Identifier id;

4. Print문
- Print문은 수식(Expr)로 구성됨
- Print = Expr expr;

5. 복합문
- 복합문(Compound)은 여러 개의 문장들(Stmts)로 구성된다
- Stmts = Stmt*

- AST는 다음과 같이 ArrayList를 이용하여 구현할 수 있음
class Stmts extends Stmt{
public ArrayList<Stmt> stmts = new ArrayList<Stmt>();
}6. 조건문
- 조건문은 조건식 Expr과 then 부분 문장(Stmt)과 else 부분 문장(Stmt)으로 구성
- If = Expr expr; Stmt stmt1; Stmt stmt2

7. While문
- While문은 조건식(Expr)과 본체 문장(Stmt)으로 구성

8. Let문
- Let문은 변수 선언들(Decls)과 여러 실행문들(Stmts)로 구성
- Let = Decls decls; Stmts stmts;

3.3 어휘 분석기
1) 토큰
- 어휘 분석(lexical analysis): 소스 프로그램을 읽어 들여 토큰(token)이라는 의미 있는 문법 단위로 분리하는 것
- 구문 분석을 하면서 다음 토큰이 필요할 때마다 어휘 분석기를 호출하는 것이 일반적
1. 예약어
- 언어에서 미리 그 의미와 용법을 지정되어 사용되는 단어로 예약어 또는 키워드라고도 함
- 언어 S의 예약어 이름과 해당하는 스트링은 다음과 같음
BOOL("bool"),CHAR("char"), ELSE("else"), FALSE("false"), FLOAT("float"),
STRING("string"), IF("if"), INT("int"), TRUE("true"), WHILE("while"),
RETURN("return"), VOID("void"), FUN("fun"), THEN("then"), LET("let"),
IN("in"), END("end"), READ("read"), PRINT("print")
2. 식별자
- 변수 혹은 함수의 이름을 나타내며 토큰 이름은 ID라고 함
- 식별자는 첫 번째에 오는 것이 문자이고 이어서 0개 이상의 문자 혹은 숫자들로 이루어진 스트링
ID = letter(letter | digit)*
letter = [a-zA-Z]
digit = [0-9]
3. 정수 리터럴
- 정수 리터럴은 정수 상수를 나타내며 토큰 이름은 NUMBER라고 함
NUMBER = digit^+
4. 스트링 리터럴
- 스트링 리터럴은 문자열을 나타내며 토큰 이름은 STRLITERAL이라고 함
STRLITERAL = "..."
5. 연산자
- 언어 S에서 사용되는 연산자를 다음과 같이 토큰으로 정의
ASSIGN("="), EQUAL("=="), LT("<"), LTEQ("<="), GT(">"),
GTEQ(">="), NOT("!"), NOTEQ("!="), PLUS("+"), MINUS("-"),
MULTIPLY("*"), DIVIDE("/"), AND("&"), OR("|")
6. 구분자
- 언어 S에서 사용되는 구분자를 다음과 같이 토큰으로 정의
EOF("<<EOF>>"), LBRACE("{"), RBRACE("}"), LBRACKET("["), RBRACKET("]"),
LPAREN("("), RPAREN(")"), SEMICOLON(";"), COMMA(",")
2) 정규식
- 특정한 규칙을 가진 문자열의 집합을 표현하는데 사용
- 정규식은 다음과 같이 재귀적으로 정의할 수 있음. M과 N이 정규식 일 때 다음 표현은 모두 정규식임

- 추가적으로 다음과 같은 간단 표기법을 사용할 수 있음

'Study > Programming Language' 카테고리의 다른 글
| [PL] Chapter 04. 변수 및 유효범위 (2) | 2022.04.25 |
|---|---|
| [PL] Chapter 02. 구문법(Syntax) (0) | 2022.04.24 |
| [PL] Chapter 01. 서론 (0) | 2022.04.23 |
