W6: Double Linked List(CRUD) 구현, 어셈블리로 구구단 구현, Stack 개념 공부하기
참고 자료: 자료구조 개념 및 구현 - 유석종 교수님(자료구조 수업 교재), Stack 참고자료 - 제공해주신 .md 파일
# 1. Double Linked List(CRUD) 구현
- SLL(Single Linked List)의 문제점: 다음 노드만 알고 이전 노드는 알 수 없음
- DLL(Double Linked List)
- 각 노드는 이전 노드와 이후 노드의 정보를 알 수 있음
- 삽입/삭제가 용이함
- 헤드 노드 필요: 데이터를 가지지 않고, 삽입/삭제 코드를 간단하게 할 목적으로 만들어진 노드
- head node와 tail노드를 각각 사용할 수도 있지만 교재에서는 head node만을 사용하여 circular or non-circular DLL을 설명함
- 구성 필드: data, left link(llink), right link(rlink)
- DLL의 선언
typedef struct node node_type * node_prt; // node_type의 포인터 변수 선언
struct node_type{
node_ptr llink; // 왼쪽으로 연결되는 llink
int data;
node_ptr rlink; // 오른쪽으로 연결되는 rlink
}
- 양방향 리스트의 노드 삽입
1. 노드의 llink를 prev 노드로 연결
2. 노드의 rlink를 prev 다음 노드로 연결
3. prev 다음 노드의 llink가 노드를 참조하도록 연결
4. prev 노드의 rlink가 노드를 참조하도록 연결

void insert_dll(node_ptr prev, node_ptr node){
node->llink = prev;
node->rlink = prev->rlink;
prev->rlink->llink = node;
prev->rlink = node;
}
- 양방향 연결 리스트의 노드 삭제
1. 삭제할 노드가 head 노드이면 삭제 불가능 메시지 출력 후 종료
2. 일반 노드의 삭제일 경우 삭제할 이전 노드(node->llink)의 rlink에 삭제할 노드의 다음 노드 주소(node->rlink)를 저장
3. 삭제할 노드의 다음 노드(node->rlink)의 llink에 이전 노드(node->llink)를 복사
4. 삭제할 node의 메모리 반환

void delete_dll(node_ptr head, node_ptr node){
if(head==node)
printf("Head node not deleted\n");
else{
node->llink->rlink = node->rlink;
node->rlink->llink = node->llink;
free(node);
}
}
- DLL(CRUD) 구현
#include <stdio.h>
#include <stdlib.h>
typedef struct node_type *node_ptr;
struct node_type{
node_ptr llink;
int data;
node_ptr rlink;
};
void insert_dll(node_ptr prev, node_ptr node);
void delete_dll(node_ptr head, node_ptr node);
void edit_dll(node_ptr head, int search, int change);
void print_dll(node_ptr head);
node_ptr head;
int main() {
node_ptr node1, node2, node3, node4;
head = (node_ptr)malloc(sizeof(struct node_type));
node1 = (node_ptr)malloc(sizeof(struct node_type));
node1 -> data = 7;
head -> llink = NULL;
head -> rlink = node1;
node1 -> llink = head;
node1 -> rlink = NULL;
node2 = (node_ptr)malloc(sizeof(struct node_type));
node2 -> data = 13;
node1 -> rlink = node2;
node2 -> llink = node1;
node3 = (node_ptr)malloc(sizeof(struct node_type));
node3 -> data = 15;
node2 -> rlink = node3;
node3 -> llink = node2;
node3 -> rlink = head;
head -> llink = node3;
node4 = (node_ptr)malloc(sizeof(struct node_type));
node4 -> data = 11;
node4 -> llink = NULL;
node4 -> rlink = NULL;
print_dll(head);
delete_dll(head, node1);
print_dll(head);
insert_dll(node2, node4);
print_dll(head);
edit_dll(head, 11, 10);
print_dll(head);
return 0;
}
void insert_dll(node_ptr prev, node_ptr node){
node->llink = prev;
node->rlink = prev->rlink;
prev->rlink->llink = node;
prev->rlink = node;
}
void delete_dll(node_ptr head, node_ptr node){
if(head==node)
printf("Head node not deleted\n");
else{
node->llink->rlink = node->rlink;
node->rlink->llink = node->llink;
free(node);
}
}
void edit_dll(node_ptr head, int search, int change){
node_ptr start = head -> rlink;
while(start != head){
if(start->data == search){
start->data = change;
break;
}
else start = start->rlink;
}
}
void print_dll(node_ptr head){
node_ptr start = head -> rlink;
while(start != head){
printf("%d ", start->data);
start = start -> rlink;
}
printf("\n");
}수업시간에 다루지 않았던 것이 edit_dll 인데 이것은 single linked list에서 data를 수정하는 부분을 참고해 구현하였다
- 실행 결과

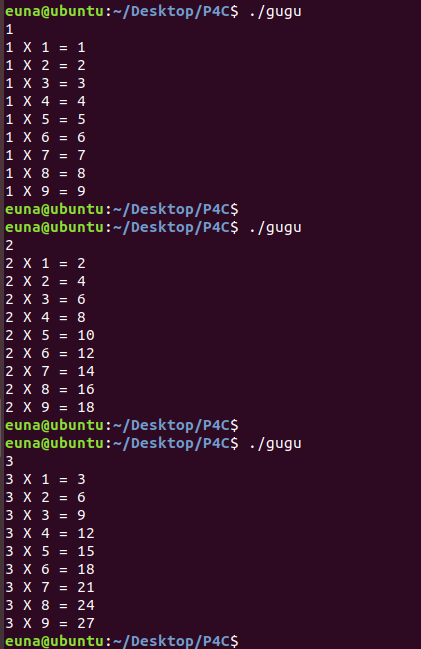
# 2. 어셈블리로 구구단 구현
- 실행 환경 및 컴파일 방법
- Linux: Ubuntu 18.04
$ nasm -f elf64 파일명.s -o 파일명.o
$ ld 파일명.o -o 파일명
* nasm 명령어가 없다면 아래 명령어를 통해 설치해주면 된다
$ sudo apt-get install build-essential gcc-multiplib nasm
- 구구단 출력 프로그램 작성하기 in assembly
global _start
section .text
_start:
; read number
xor rax, rax
xor rdi, rdi
mov rsi, input
mov rdx, 1
syscall ;sys_read
; print result a X b = c\n
mov rcx, 9 ; repeat count
mov rax, '1'
print:
push rax
push rcx
mov [num], al
mov rax, 1 ; print position of a
mov rdi, 1
mov rsi, input
mov rdx, 1
syscall ; sys_write
call printX ; print multiplication sign
mov rax, 1 ; print position of b
mov rdi, 1
mov rsi, num
mov rdx, 1
syscall ; sys_write
call printequal ; '=' print
call printres ; print position of c
call printenter ; print '\n'
pop rcx
pop rax
inc al
loop print
; exit
mov rax, 60
xor rdi, rdi
syscall
printX:
mov rax, 1
mov rdi, 1
mov rsi, x
mov rdx, 3
syscall ; sys_write
ret
printequal:
mov rax, 1
mov rdi, 1
mov rsi, equal
mov rdx, 3
syscall ; sys_write
ret
printenter:
mov rax, 1
mov rdi, 1
mov rsi, enter
mov rdx, 1
syscall ; sys_write
ret
printres:
mov al, [input]
sub al, '0'
mov bl, [num]
sub bl, '0'
mul bl
mov bl, 10
div bl
add al, '0'
add ah, '0'
cmp al, '0'
je one
mov [res+1], ah
mov [res], al
mov rax, 1
mov rdi, 1
mov rsi, res
mov rdx, 2
syscall ; sys_write
ret
one:
mov [res], ah
mov rax, 1
mov rdi, 1
mov rsi, res
mov rdx, 1
syscall ; sys_write
ret
section .data
input: dw 0x00
x: dw ' X '
num: db '1'
equal: dw ' = '
res: dw '1'
enter: dw 10
- 정리
- section .text: 실행할 코드가 저장되는 영역으로 전체 코드를보면 _start부터 printres까지 정의되어 있다
- section .data: 초기화한 전역변수 선언 영역
section .text
_start:
printX:
printequal:
printenter:
printres:
---------------------------------
section .data
input: dw 0x00
x: dw ' X '
num: db '1'
equal: dw ' = '
res: dw '1'
enter: dw 10- 데이터 지시어
| 문자(Letter) | dx | resx | 단위(unit) | another name |
| b | db | resb | 1바이트 | 바이트(byte) |
| w | dw | resw | 2바이트 | 워드(word) |
| d | dd | resd | 4바이트 | 더블 워드(double word, dword) |
| q | dq | resq | 8바이트 | 쿼드 워드(quard word, qword) |
| t | dt | rest | 10바이트 | 텐 바이트(ten byte, tbyte) |
- 변수의 값을 변경하는 방법: 변수를 []로 감싸야 변수가 담고있는 실제 값이 변경됨 (그렇지 않을 경우 메모리 주소를 변경하는 코드가 된다고 한다)
- syscall 사용(x64)
| syscall | rax | arg0(rdi) | arg1(rsi) | arg2(rdx) |
| read | 0x00 | unsigned int fd | char *buf | size_t count |
| write | 0x01 | unsigned int fd | const char *buf | size_t count |
- 레지스터에 대한 이해
[Dreamhack] Background: Computer Architecture
Background: Computer Architecture # 서론 - 컴퓨터는 각자 다른 기능을 수행하는 여러 부품들의 도움으로 작동 - CPU: 컴퓨터 작동에 핵심이 되는 연산을 처리하고, 저장 장치는 데이터를 저장 - 이외에도
fascination-euna.tistory.com
- 실행 결과


# 3. 제공된 스택 설명 문서 한 장으로 요약하기
1) Stack이 필요한 이유: 지역변수
- 지역변수: 함수가 실행 될 때마다 그 영역이 생성되고 사용되어짐. 함수의 실행이 끝나게 되면, 이 영역은 사라지고 사용하지 못하게 됨
- stack에는 한 개의 함수가 실행 될 때마다 함수가 소유할 수 있는 하나의 영역이 생성됨. 함수가 끝나게 될 때, 이 영역은 자동으로 삭제됨
- 따라서 지역변수를 위해 채택된 방법이 stack인 것임
- 예시
int func1(void) {
int val1 = 1;
return val1;
}
int func2_1(void) {
int val2_1 = 2;
return val2_1;
}
int func2_2(void) {
int val2_2 = 2;
return val2_2;
}
int func2(void) {
int val2 = 2;
val2 += func2_1();
val2 += func2_2();
return val2;
}
int func3(void) {
int val3 = 3;
return val3;
}
int main(void) {
func1();
func2();
func3();
return 0;
}코드가 다음과 같을 때 스택은 아래와 같은 흐름을 가지게 됨

2) Stack 실습
- 컴파일 옵션 및 실습 코드
// gcc -o stack stack.c -no-pie -fno-stack-protector
#include <stdio.h>
int func1(void) {
int val1 = 1;
printf("func1(): %p\n", &val1);
return val1;
}
int func2_1(void) {
int val2_1 = 2;
printf("func2_1(): %p\n", &val2_1);
return val2_1;
}
int func2_2(void) {
int val2_2 = 2;
printf("func2_2(): %p\n", &val2_2);
return val2_2;
}
int func2(void) {
int val2 = 2;
printf("func2(): %p\n", &val2);
val2 += func2_1();
val2 += func2_2();
return val2;
}
int func3(void) {
int val3 = 3;
printf("func3(): %p\n", &val3);
return val3;
}
int main(void) {
int valmain = 0;
printf("main(): %p\n", &valmain);
func1();
func2();
func3();
return valmain;
}- 실행 결과: 현재 함수가 가지고 있는 지역 변수의 주소값을 출력4

위에서 학습한 스택 흐름과 주소를 연관지어 그려보면 아래와 같음

각 함수마다 한 개의 int형 변수를 선언했기 때문에 위와 같이 모든 함수의 스택 크기가 동일
but, int형 자료형은 4바이트 크기의 자료형이나 함수의 실제 할당은 32비트임을 알 수 있음
이를 위해 gdb를 사용해서 프로그램을 분석해볼 것
- gdb를 사용해서 프로그램 분석

main() 함수의 디스어셈블리와 func1() 함수의 디스어셈블리의 처음과 끝에 같은 코드가 사용되고 있음
이 처음과 끝을 각각 함수의 프롤로그, 에필로그라고 부름
3) Stack base pointer
- stack base pointer의 역할
- 지역변수의 번지수를 계산하기 위한 base pointer
- 현재 함수의 스택을 정리 시 사용

rpb = 0x4018이며 이 값을 기준으로 variable1을 참조하기 위해서는 0x18만큼 빼면됨
스택에서 지역변수의 절대 주소값을 알기는 매우 어렵기 때문에 절대적인 주소를 아는 것 보다 좀 더 효율적인,
base pointer에서 오프셋을 계산하는 방식으로 구현되어 있음
4) call, ret 명령어
- call 명령어
push rip+5 ;호출할 함수가 끝난 다음 실행해야 하는 코드의 주소값을 스택에 push
jmp ~ ; 함수 호출- ret 명령어
pop rip ; 스택에 있는 값을 pop하여 명령어 포인터 레지스터에 저장
5) 함수의 프롤로그, 에필로그에 대해
- context: 함수의 문맥
- 함수의 실제 코드(instruction pointer)
- 함수에 전달된 인자들(arguments)
- 함수가 사용하는 지역변수들의 주소(stack base pointer)
- 함수가 끝나면 돌아갈 주소(return address)
- a 함수가 b 함수를 호출하면, b 함수는 b 함수만의 context를 가지게 되고, b 함수가 끝나게 되면 다시 a 함수의 context로 복원시켜야 함
- 함수의 에필로그
leave ; rbp 레지스터의 값을 rsp 에 대입한 후에 스택에서 pop 하여 rbp 레지스터에 대입
ret- leave 명령어는 다음 두 개의 명령어의 조합이라고 생각하면 됨
**leave: mov rsp, rbp**
```
+----...----+ +----...----+
| | <- rsp | |
| | | |
| ... | => | ... |
| | | |
| saved rbp | <- rbp | saved rbp | <- rbp, rsp
+----...----+ +----...----+
```
**leave: pop rbp**
```
+----...----+ +----...----+
| | | |
| | | |
| ... | => | |
| | | |
| saved rbp | <- rbp, rsp | |
+----...----+ +----...----+ <- rsp
```
- 함수의 에필로그와 프롤로그
- 함수가 호출되면, 함수가 끝나고 나면 실행해야하는 코드의 주소를 스택에 저장
- 함수가 실제로 호출됨
- 호출된 함수의 프롤로그가 실행됨
- 이전 함수에서 사용되던 stack base pointer의 값을 스택에 저장
- 현재 함수의 stack base pointer를 설정
- 컴파일 시 계산된 현재 함수가 사용해야하는 만큼의 스택 영역을 할당
- 호출된 함수의 실제 코드가 실행됨
- 호출된 함수의 에필로그가 실행됨
- 어디 있는지 모를 stack pointer를 원래대로 복구시킴
- 스택에 저장된 이전 함수의 stack base pointer 값을 복원시킴
- 스택에 저장해둔 이전 함수의 코드 주소로 돌아감
- 프롤로그, 에필로그의 구현
- 함수를 호출하기 전, 현재의 context에 대해 저장
- 함수가 실행됨
- 함수는 자신의 context를 정리
- 함수는 이전 context를 복구시킴
6) deep dive into binary!

main() 함수에서 func2() 함수를 호출하기 전에 break point를 설정하고 run
이제 실제 함수의 호출과 프롤로그가 어떻에 이루어지는지 볼 것
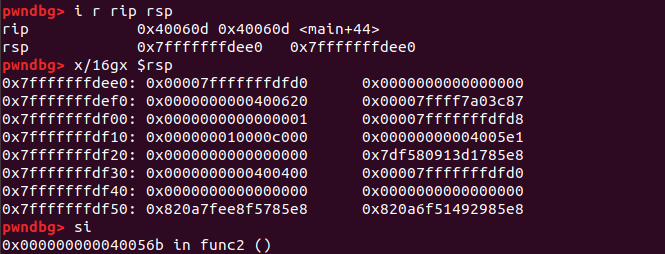

call 명령어를 실행하자, 0x0000000000400612 라는 값이 스택에 push되고,
func2 함수로 명령어 포인터(instruction pointer, rip)가 변경된 것을 알 수 있음

0x0000000000400612 의 주소값은 코드 영역이고,
이 값을 확인해보면 func2 함수가 끝난 후 실행해야 할 main 함수의 코드인 것을 알 수 있음
이제 함수의 프롤로그를 확인해 볼 것

명령어를 하나씩 실행
** push rbp**


rbp의 값이 스택에 push된 것을 확인할 수 있음
** mov rbp, rsp **


현재 함수의 rbp가 설정됨
** sub rsp, 0x10 **

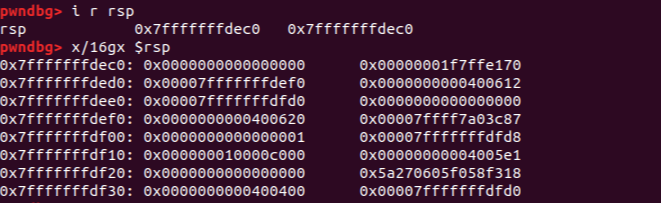
함수에서 사용할 만큼(0x10)의 스택 공간이 만들어짐
이제 함수의 에필로그를 확인하기 위해 break point를 설정하고 실행할 것임

** leave **


rsp와 rbp가 복원된 것을 확인할 수 있음
** ret **


func 함수가 끝난 후 실행해야 할 코드의 주소로 반환되었음
7) Stack이 필요한 이유: 프로그램의 흐름
- 지역변수라는 특성과 더불어 프로그램의 흐름에도 stack의 역할이 중요함
- 다음 개념들에 대해 함께 공부하면 도움이 될 것
- caller, callee
- saved register
- calling convention
'etc... > 빡공팟(P4C) 4기' 카테고리의 다른 글
| [P4C] W8: Out of bounds & R/W primitives 취약점 공부하기 (0) | 2022.06.12 |
|---|---|
| [P4C] W7: 올드 스쿨 취약점과 올드 스쿨 공격 기법 공부하기 (0) | 2022.06.05 |
| [P4C] W4-W5: C언어로 HTTP 서버 구현 (0) | 2022.05.21 |
| [P4C] W3: 코드업 기초 100제 70번 대 이후 문제들 중 가장 어려웠던 10문제 write-up 작성하기 (0) | 2022.05.08 |
| [P4C] W2: 코드업 기초 100제 70번 이하 문제들 중 가장 어려웠던 5문제 write-up 작성하기 (0) | 2022.04.29 |
