1. Reversing Engineering - 2. x64 기초
1.1. 1. Introduction
1.1.1. # Intorduction
- 디스어셈블 과정을 거쳐 나온 어셈블리 코드를 이해하기 위해 어셈블리 코드에 대해 공부할 것
- 어셈블리 코드는 기계 코드와 1:1 대응
- 기계 코드가 실제로 동작할 CPU에 따라 기계 코드 역시 달라지게 됨
> CPU에 따라 어셈블리 코드도 다름
1.2. 2. 들어가기에 앞서
1.2.1. # Instruction Cycle
- 어셈블리 코드는 기계 코드와 대응되므로, 기계 코드가 동작할 CPU가 어떤 역할을 하고 어떻게 동작하는지 알아보는 것이 어셈블리 코드를 이해하는데 도움이 됨
- CPU의 기본적인 동작 과정
> CPU: 다음 실행할 명령어를 읽어오고(Fetch) → 읽어온 명령어를 해석한 다음(Decode)
→ 해석한 결과를 실행하는(Execute) 과정을 반복하는 장치
> 한 개의 명령어, 즉 기계 코드가 실행되는 한 번의 과정을 Instruction Cycle이라고 함
> CPU를 구성하는 요소들은 효율적인 수행을 위해 필요한 것들임
1.2.2. # 레지스터(Register)와 명령어(Instruction)
- CPU: Instruction Cycle을 수행하기 위해 기계 코드에 해당하는 각종 명령어를 해석하기 위한 구성 요소 외에도 읽어온 명령어가 저장된 공간을 임시로 기억해 둘 구성 요소나, 명령어를 실행한 결과를 저장해 둘 구성요소 필요
- 레지스터: CPU 동작에 필수적인 저장 공간의 역할을 하는 CPU의 구성 요소
- CPU가 실행할 명령어들은 수행하는 동작에 따라 조금씩 형태가 다름
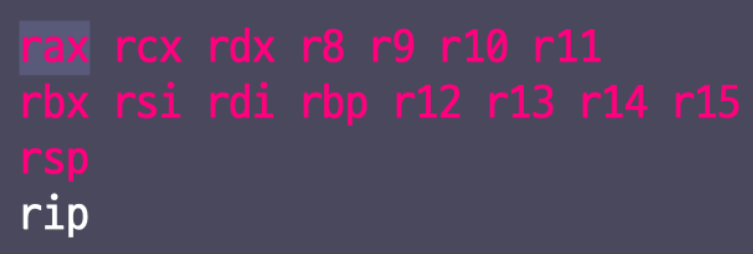
1.3. 3. 레지스터
1.3.1. # 레지스터
- 레지스터: CPU가 사용하는 저장 공간
> 특별히 쓰임새가 정해져 있지 않음
> 하지만 관행적으로 정해놓고 쓰는 레지스터도 있고, 엄격히 정해진 용도로만 쓰이는 레지스터도 있음
1.3.2. # 범용 레지스터
- 범용 레지스터(General-Purpose Gegisters, GPR): 특별히 정해두지 않고 다양하게 쓸 수 있는 레지스터
> CPU는 범용 레지스터를 연습장처럼 씀
- x64의 범용 레지스터는 총 16개로, 아래 빨간 글씨로 표시된 레지스터들이 여기에 해당됨
> 원칙적으로는 용도가 정해져 있지 않지만, 관행적으로 그 쓰임새가 정해져 있는 경우도 있음

- rax(accumulator register): 함수가 실행된 후 리턴 값을 저장하기 위해 쓰임
> 어떤 함수의 실행이 종료되고 나면 해당 함수의 결괏값이 반환될 때 이 rax 레지스터에 담겨 반환됨
> 하지만 리턴 값을 위해서만 쓰이는 것은 아니며 함수가 반환되기 전까지는 범용 레지스터로 자유롭게 사용됨
> 함수 종료 후 리턴값을 반환하기 위한 레지스터는 rax만 사용됨
- 함수 호출 규약(Calling convention): x64의 범용 레지스터들 중에서 함수가 실행될 때 필요한 인자들을
저장하는 용도로 사용하는 레지스터
> 운영체제의 종류나 함수의 종류에 따라 조금씩 다름
> rcx, rdx, r8, r9: Windows 64bit에서 함수를 호출할 때 필요한 인자들을 순서대로 저장
> 즉, 첫 번째 인자는 rcx에, 두 번째 인자는 rdx에... 하는 방식으로 인자를 레지스터에 담아 함수를 호출
> 함수 호출 규약에서 쓰이는 레지스터들 역시 함수를 호출할 때 인자를 전달하는 용도로 레지스터들이 정해짐
> 함수가 호출된 이후에는 범용 레지스터로 자유롭게 사용할 수 있음
- rsp: 16개의 범용 레지스터들 중 하나로 분류되지만, 다른 범용 레지스터들과 달리 용도가 정해져 있음
> 스택 포인터(Stack Pointer)로, 스택의 가장 위쪽 주소를 가리킴
> 스택은 함수가 사용할 지역 변수(local variables)들을 저장하기 위해 준비해놓는 공간
1.3.3. # 명령어 포인터
- 명령어 포인터(Instruction pointer): 범용 레지스터들과 달리 용도가 엄격하게 정해져 있음
> rip: 다음에 실행될 명령어가 위치한 주소를 가리키고 있음
> 즉, 프로그램의 실행 흐름과 관련된 중요한 레지스터이므로, 범용으로 사용되지 않는 레지스터
1.3.4. # Data Size
- CPU가 사용하는 값의 크기 단위를 WORD라고 함
- 16bit CPU가 처음 등장했을 당시 CPU가 사용하는 값의 단위였던 16bit를 WORD라고 하면서, WORD 단위를 처리할 수 있는 범용 레지스터의 이름이 ax, cx, dx, bx로 붙은 것이 현재 우리가 사용하는 레지스터 이름의 기원이 되었음
- 시간이 흘러 32bit 단위로 레지스터의 크기가 커지면서 레지스터의 이름도 eax, ecx, edx, ebx가 되었음
- 64bit CPU인 x64의 레지스터들이 담을 수 있는 값의 크기: 8byte, QWORD
> 8byte 단위로만 값을 저장해야 하는 것은 아님
> rcx 레지스터를 예로 들어 설명하면 rcx레지스터에 저장된 값 중 하위 32bit (4byte, DWORD)만
연산에 사용할 수도 있고, 혹은 하위 16bit(2byte, WORD)나 하위 8bit(byte, BYTE)만 사용하는 것도 가능
> 레지스터의 하위 비트만 접근하려면 어셈블리 코드에서 접근할 레지스터 이름으로 ecx, cx를 사용하면 됨
- r8 ~ r15까지 64비트에서 새로 추가된 범용 레지스터들도 하위 일부 비트만 접근하여 사용하기 위해 다른 레지스터 이름을 사용할 수 있음
> r8의 경우 r8d, r8w, r8b를 통해 각각 하위 32비트, 16비트, 8비트에 접근 가능
> 이렇게 d, w, b와 같은 접미사를 붙이는 방식은 r8 ~ r15 레지스터들이 동일하게 사용
1.3.5. # FLAGS
- FLAGS: 상태 레지스터
> '깃발'을 의미하는 단어 뜻 그대로, 현재 상태나 조건을 0과 1로 나타내는 레지스터
> 앞서 본 레지스터들과 달리, FLAGS 레지스터를 구성하는 64개의 비트를 각각이 서로 다른 의미를 지님
> 0번째 비트, 1번째 비트, 2번째 비트... 등 각각의 비트가 서로 다른 상태를 나타냄




1.4. 4. Instruction Format
1.4.1. # Opcode (Operation Code)
- 명령 코드(Opcode, Operation Code): 명령어에서 실제로 어떤 동작을 할지를 나타내는 부분
- 기계 코드(Machine Code) 또는 명령 코드(Opcode)라고 부름
> 컴파일러가 만드는 결과물인 바이너리를 구성하고 있으며, CPU가 실제로 수행할 작업을 나타내는 숫자
> 디버거를 사용해 프로그램을 보면, 하단에 보이는 결과와 같이 왼쪽의 숫자들처럼 생긴 명령 코드를 확인할 수 있음
> 이 명령 코드는 CPU의 종류별로 다른 값일 수 있으며, 명령 코드에 따라 피연산자가 필요하기도 함
- 어셈블리 코드 (Assembly Code)
> 숫자로 이뤄져 있는 명령 코드는 사람이 구분하고 이해하기 쉽지 않기 때문에 명령 코드가 어떤 의미를 갖는지
알아보기 쉽도록 문자로 작성된(Mnemonic) 코드
> 명령 코드를 알아보기 쉽도록 문자로 치환한 것이므로, 명령 코드와 1:1 대응
> 명령 코드가 연산할 때 사용할 피연산자도 알아보기 쉬움
> CPU의 동작을 그대로 옮겨놓은 것에 가깝기 때문에 매우 직관적이고 단순한 반면,
실제 소스코드와 달리 고차원적인 전체 흐름을 파악하기는 어려움
1.4.2. # Operand
- 피연산자(operand): 명령 코드가 연산할 대상
> 명령 코드를 함수라고 생각하면, 피연산자는 함수에 들어가는 인자로 비유 가능
> 명령 코드에 따라 조금씩 다를 수 있지만, intel 방식의 어셈블리를 읽을 때에는 명령 코드에 따라
연산한 결과를 왼쪽 피연산자에 저장한다고 이해하는 것이 일반적
> 명령 코드가 작업을 수행할 대상인 피연산자는 어떤 상수일 수도 있고, 레지스터에 들어 있는 값일 수도 있으며,
어떤 주소에 들어있는 값일 수도 있음
> 피연산자를 어떻게 지정해 줄 것인지는 그 값을 사용할 방식에 따라 다양함
1.4.3. # Operand Types
- 주어진 명령 코드의 피연산자로는 상수, 레지스터, 혹은 레지스터가 가리키고 있는 메모리의 어떤 주소가 올 수 있음
1) 상수값(Immediate)
> 피연산자로 사용되는 값이 상수인 경우
> 아래 예시: mov 명령어의 피연산자 중 하나로 0xbeef가 사용됨
2) 레지스터
> 레지스터도 피연산자로 사용될 수 있음
> 이 경우에는 레지스터에 들어있는 값이 피연산자로 사용됨
> 아래 예시를 보면, mov 명령어의 결과로 rbx에 들어있는 값이 rcx에 들어가게 됨
3) Addressing Modes
> 레지스터에 저장된 메모리 주소를 참조한 값이 피연산자가 되는 경우
> 레지스터에 들어있는 값은 메모리 주소로, 실제로는 해당 메모리 주소를 참조한 값이 피연산자로 사용됨
> C언어의 포인터 개념과 유사
> 설명 및 예시
*16진수 뒤에 h가 붙는 것은 hex라는 의미임
1.5. 5. Instructions
1.5.1. # Data Movement
- mov: src에 들어있는 값을 dst로 옮김
- lea: Load Effective Address로, dst에 주소를 저장
1.5.2. # Arithmetic Operations
- 산술 연산: FLAGS 레지스터 CF, OF, ZF 등과 관련이 있음
1) Unary Instructions
> inc, dec: dst의 값을 1 증가시키거나 감소시킴
> neg: dst에 들어 있는 값의 부호를 바꿈(2의 보수)
> not: dst에 들어 있는 값의 비트를 반전(bitwise inverse)
2) Binary Instructions
> add: dst에 들어있는 값에 src를 더함
> sub: dst에 들어있는 값에 src를 뺌
> imul: dst에 들어있는 값에 src를 곱함
> and: dst에 들어있는 값과 src 간에 AND 논리 연산을 한 결과를 dst에 저장
> or: dst에 들어있는 값과 src간에 OR 논리연산을 한 결과를 dst에 저장
> xor: dst에 들어있는 값과 src간에 XOR 논리연산을 한 결과를 dst에 저장
3) Shift Instruction
> shl, shr: dst의 값을 k만큼 왼쪽이나 오른쪽으로 shift 함. 이때 shift는 logical shift이므로,
shr의 경우 오른쪽으로 shift 할 때 빈 bit 자리에는 0이 채워짐
> sal, sar: dst의 값을 k만큼 왼쪽이나 오른쪽으로 shift 하는 것은 같지만, arithmetic shift이기 때문에 부호가 보전됨.
따라서 sar은 최상위 비트(MSB, Most Significant Bit)가 shift 이후에도 보전됨
1.5.3. # Conditional Operation
- 분기문이나 조건문과 같이 코드의 실행 흐름을 제어하는 것과 밀접한 연관이 있는 연산
- 특히 분기에서 어떻게 코드의 실행 흐름을 정할지는 앞서 공부한 FLAGS 레지스터의 각종 플래그와 밀접한 관련이 있기 때문에, 각각의 명령어가 어떤 플래그의 영향을 받는지를 아는 것이 중요
1) test
> test dst, src: and와 마찬가지로 AND 논리 연산을 하지만, 결괏값을 피연산자에 저장하지 않는다는 특징이 있음.
> and dst, src의 결과는 dst에 저장되지만, test 명령어에서는 그렇지 않음
> test의 연산 결과는 FLAGS 레지스터에 영향을 미침
> 두 피연산자에 대해 AND 연산을 한 경우가 음수이면(최상위 비트가 1이면) SF가 1이 되고,
AND 연산의 결과가 0이면 ZF를 1로 만듦
> 레지스터에 들어있는 값이 음수인지, 혹은 0인지를 확인하는 데에 유용하게 쓰임
2) cmp
> cmp dst, str: sub와 마찬가지로 dst에서 src를 빼지만, 그 결괏값이 피연산자인 dst에 저장되지 않고
FLAGS 레지스터의 ZF와 CF 플래그에만 영향을 미친다는 점에서 test와 유사
> dst=src일 때에는 ZF=1, CF=0이 되고, dst <src일 때에는 ZF=0, CF=1, 반대로 dst> src일 때에는 ZF=0, CF=0이 됨
3) jmp, jcc
> jmp: 무조건 점프
> jcc: 조건에 따라 점프의 수행 여부가 달라짐 → 사용하는 조건이 FLAGS 레지스터의 플래그와 밀접한 관련 있음
jcc의 경우에 점프 명령어를 수행하기 전에 어떤 산술 연산을 하거나, test, cmp 등의 연산을 수행한 결과로
바뀐 플래그를 바탕으로 점프의 수행 여부를 결정
> jcc는 명령어의 이름이 아니라, 조건부 jmp를 묶어서 이르는 이름(Jump if condition is met)
> 예시
> 1. cmp 명령어의 결과를 바탕으로 jle 명령어를 수행하는 내용
→ rbp 레지스터가 가리키는 주소에서 -0x2c만큼 떨어진 곳에 들어있는 값과 0x47을 비교하여,
이 값이 0x47보다 작거나 같으면(less or equal) 0x400a31로 점프
> 2. test 명령어를 수행한 결과로 je의 수행 여부가 정해지는 내용
→ rax가 0이면 test명령어를 수행한 뒤 ZF=1이 되므로, je 명령어에 의해 0x4006c5로 점프하게 됨
> 위의 2가지 예시 모두 조건을 만족하지 않을 경우 jcc를 수행하지 않고 다음으로 넘어감
1.5.4. # Stack Operations
- 프로그램이 동작하는 동안 함수 안에서 지역 변수(Local Variables)를 사용할 때가 많음
- 지역 변수는 함수가 종료되고 나면 더 이상 참조되거나 사용되지 않기 때문에, 함수 안에서는
마치 연습장과 같은 역할을 함
- 지역 변수들은 스택에 저장됨
- 지역 변수를 사용하기 위한 '연습장'인 스택은 레지스터가 아닌 메모리에 준비됨
- 새로운 함수가 시작될 때 스택이 준비되고(Function Prologue), 함수가 종료될 때 스택이 정리됨(Function Epilogue)
- 위의 과정은 레지스터들 중 스택의 가장 윗부분을 가리키는 rsp 레지스터와 밀접한 관련이 있음
- rsp revisit
> rsp: 스택 포인터로, 스택의 가장 위쪽 주소를 가리킴
> 스택에 새로운 데이터를 담을수록 스택은 점점 길어짐
> 마지막으로 담은 데이터 위에 새로운 데이터를 쌓아가는
방식으로 길어지게 됨
> 스택의 가장 위쪽은 마지막으로 데이터가 담긴 메모리 주소
> rsp는 스택의 가장 위쪽을 가리키므로, 마지막으로 데이터가
추가된 위치를 저장하는 레지스터
> 스택이 자라는 방향은 아키텍처에 따라 다름
> 아키텍처에 따라 새로운 데이터가 추가될 때 더 높은 메모리
주소에 쌓이는 경우도 있고, 그 반대의 경우도 있음
> Intel x86-64 아키텍처에서 스택은 낮은 주소(=더 작은 숫자)를
향하게 자라기 때문에 스택이 자랄수록 rsp에 저장된 메모리
주소는 점점 낮아짐
1.5.5. # Function Prologue/Epilogue
- 함수가 시작될 때(Function Prologue)에는 rsp 레지스터에 들어있는 주소에서 충분한 값을 빼줌
> 이렇게 하면 rsp가 가리키는 곳을 낮은 주소로 당겨오는 효과가 있기 때문에,
함수 안에서 지역 변수를 사용하기 위한 공간을 확보하는 효과가 생김
> 이때 rsp를 얼마나 내릴 것인지, 즉 스택을 어느 정도의 크기로 확보할 것인지는 컴파일러가 최적화를 통해 결정
- 함수가 끝날 때(Function Epilogue)에는 프롤로그에서 빼준 값만큼 다시 rsp에 더해줌
> 이렇게 스택 포인터를 복원하면 함수에서 사용했던 스택을 정리하는 효과를 볼 수 있음
1.5.6. # push, pop
- push, pop 명령어는 스택에 새로운 데이터를 추가하거나 뺄 때 사용
- 스택에 새로운 데이터를 넣는 명령어는 push
> 새로운 데이터가 들어가면 rsp 레지스터도 새로운 데이터가 들어간 주소를 가리켜야 하므로,
아래 예시에서와 같이 push는
1) rsp가 가리키는 주소에서 들어갈 데이터의 사이즈만큼 빼서 데이터가 들어갈 크기를 확보한 뒤
2) 데이터를 복사하는 과정과 동일한 효과를 냄
- pop은 push와 반대로 스택의 최상단에 있는 데이터를 빼내는 명령어이므로, 그 반대 순서로 진행하는 것과 동일함
1.5.7. # Procedure Call Instruction
1) call
> 함수를 실행할 때에는 call 명령어가 쓰임
> call은 피연산자로 실행할 함수의 주소를 받음
> call로 호출한 함수가 종료되고 나면 다음 명령어를 실행할 장소로 돌아와야 함
즉, call을 사용한 이후에 실행되어야 하는 명령어의 주소가 어디인지 기억해둬야
함수가 종료된 다음에도 프로그램의 실행을 이어갈 수 있음
> 위와 같이 함수의 종료 이후에 돌아와야 하는 주소, 즉 리턴할 때 참조해야 할 주소를 return address라고 함
> call의 수행은 return address를 스택에 push 해 둔 다음, 호출할 함수의 주소로 jmp 하는 것과 동일한 원리로 실행됨
2) ret
> 호출된 함수가 마지막으로 사용하는 명령어 ret
> return address로 돌아가는 역학을 함
> 스택에 들어있는 return address를 pop 하여 명령어 포인터인 rip 레지스터에 넣은 다음,
그 주소로 jmp 하는 것과 동일
> ret 명령어를 사용하기 전까지는 함수에서 스택을 모두 정리한 상태
> 따라서 Function Epilogue까지 마무리되어 있으므로 rsp는 함수가 시작하기 직전에 스택에 넣은 값을 가리키고 있음
>이 값은 call 할 때 스택에 넣었던 return addres이므로, pop을 하면 스택에서 return address를 가져오게 됨
'Hacking Tech > Reversing' 카테고리의 다른 글
| [Dreamhack] Reversing Engineering - 6. 쉬운 crackme를 통한 디버거 사용법 - 1 (0) | 2021.12.21 |
|---|---|
| [Dreamhack] Reversing Engineering - 5. hello-world로 배우는 x64dbg 사용법 (0) | 2021.10.04 |
| [Dreamhack] Reversing Engineering - 4. x64dbg (0) | 2021.10.03 |
| [Dreamhack] Reversing Engineering - 3. puts("hello world!\n") → x86_64 asm (0) | 2021.10.03 |
| [Dreamhack] Reversing Engineering - 1. 리버싱 엔지니어링이란 (0) | 2021.09.16 |
